Introduction
| 1️⃣ one-shot learning이란? : test 데이터에 대한 예측을 하기 전에, 각 가능한 class당 하나의 example만 관찰할 수 있다는 제한 하에 분류를 할 수 있도록 모델을 학습하는 방법. |
이 논문에서 소개하는 방법은 siamese neural networks를 사용하여 supervised metric-based 접근법을 통해 image representation하는 것이다. 이 방법을 통해 다시 학습하지 않고 모델의 feature를 다시 사용하여 one-shot learning를 구현할 수 있다.

이 논문에서는 (이미지 인식 중) 문자 인식에 국한되어 실험하였다. 이 도메인을 위해서 논문에서는 큰 siamese CNN을 사용하였다. 이 모델은 다음과 같은 장점을 가진다.
- 새로운 분포를 위해 사용할 example이 매우 적더라도 모르는 class의 분포함수에 대해 예측을 하는데 유용한 이미지의 feature를 학습할 수 있다.
- 일반적인 최적화 방법을 사용하여 source data로부터 추출한 쌍($x_1, x_2$)으로 쉽게 학습될 수 있다.
- 딥러닝 기술을 이용하여 domain-specific한 지식에 의존하지 않아도 충분히 좋은 성능을 얻을 수 있다.
one-shot 이미지 분류 모델을 구현하기 위해
- 이미지 인식을 위한 표준의 검증 task인 이미지 쌍들의 class-identity(클래스의 동일성) 사이에 구분할 수 있도록 모델을 학습한다.- - 이때 우리는 모델이 검증을 잘하고 one-shot 분류를 잘 일반화해야 한다고 가정한다.
- 이 검증 모델이 동일한 클래스 혹은 다른 클래스에 속할 확률에 따라 입력 쌍들을 구분하도록 학습한다.
- 이 모델은 새로운 이미지들(클래스 당 하나의 이미지)로 test 이미지에 대해 쌍별로 평가된다.
- 검증 모델에 따라 가장 높은 점수를 가지는 쌍은 one-shot task에 대한 가장 높은 확률을 받게된다.
- 만약에 검증 모델로 학습된 features가 한 세트의 알파벳으로부터 문자의 동일성을 확인하거나 부인하기에 충분해지면, 다른 알파벳에 대해서도 충분해지도록 해야한다. 이를 위해 모델을 학습된 features간의 다양성을 높이기 위해 다양한 알파벳에 노출시킨다.
위 과정 중 1~2은 verification task를 위한 과정이고, 3~5는 one-shot task를 위한 과정으로 볼 수 있다.
조금 예전 논문(2015년)이라 모델 구조, 수식, 학습 알고리즘에 대해 자세하게 나와있다. meta learning 개념을 이해하는데 큰 도움을 주는 논문이기 때문에 method 부분은 자세하게 안 읽고 넘어가도 좋을 것 같다.
Method
siamese net 구조
- $L$: layer 수
- $N_l$: layer당 유닛 수
- $h_{1,l}$: 첫번째 모델의 $l$번째 layer
- $h_{2,l}$: 두번째 모델의 $l$번째 layer
- $L-2$번째 layer는 ReLU 함수를 적용하였고, 나머지 layer에는 sigmoid 함수를 적용
- 각 layer는 하나의 채널로 구성되어있고, filter 크기는 다양하며, stride는 모두 1
- output feature map에는 ReLU 함수를 사용하였고, 선택적으로 filter size와 stride 2의 max pooling을 적용
- 각 layer의 $k$번째 filter map은 다음과 같음별은 input feature map과 filter 사이의 overlap이 적용된 output feature map이 되는 유효한 convolution 연산을 의미

그렇게 해서 전체의 모델 중 하나의 구조는 다음과 같다. 전체 구조는 L-1번째 layer까지 두 모델로 구분되고, L번째 layer(FC layer)는 하나로 합쳐진 형태로 이루어진다.

- L-1번째 layer까지 두개의 모델에서 동일한 작업이 이루어지고, 두 모델의 마지막 output인 L-1번째 layer의 output feature map을 L1 component-wise 거리 연산을 통해 두 feature의 유사도를 계산한다.
학습 알고리즘
loss 함수:
- M크기의 minibatch를 적용하였을 때 i는 i번째 minibatch를 의미한다.
- $\mathsf{y}(x^{(i)}_1, x^{(i)}_2)$ : i번째 minibatch의 M개의 이미지에 대한 두 이미지 $x_1, x_2$ 의 동일성을 나타내는 값 (Mx1)
- $x_1, x_2$가 동일한 알파벳 문자 class 일때: $y(x^{(i)}_1, x^{(i)}_2)=1$
- $x_1, x_2$가 다른 알파벳 문자 class 일때: $y(x^{(i)}_1, x^{(i)}_2)=0$
- binary classifier의 cross-entropy 함수를 적용 (regularization도 적용)

최적화 알고리즘
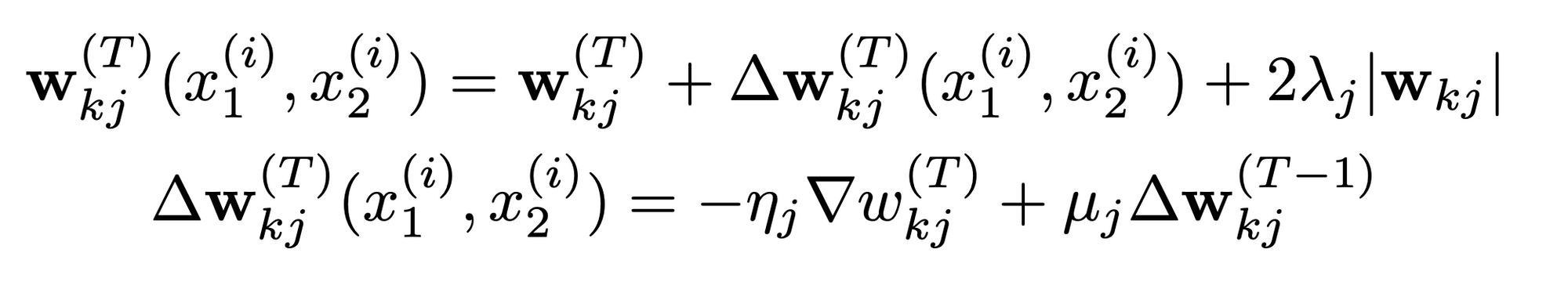
weight 초기화
- weight 분포 (convolutional layer)
- normal distribution
- mean: 0
- standard deviation : $10^{-2}$
- weight 분포 (FC layer)
- normal distribution
- mean: 0
- standard deviation : $2\times10^{-1}$
- bias 분포 (convolutional layer, FC layer)
- normal distribution
- mean: 0.5
- standard deviation : $10^{-2}$
학습 schedule
- epoch당 1% learning rate decay

- momentum: 모든 layer에서 0.5로 시작, epoch당 선형적으로 증가하여 특정값에 도달하면 멈춤
hyperparameter 최적화
- filter size : 3x3 ~ 20x20
- filter 개수 : 16 ~ 256
- FC layer 유닛 수 : 128 ~ 4096
Experiment
데이터셋
- Omniglot 데이터셋 사용
- 20명의 사람들로부터 50 종류의 알파벳(언어문자)을 손글씨로 적은 데이터
- 총 1623개의 문자(characters)에 대한 손글씨 데이터
- one-shot learning을 위한 데이터셋
- 학습/test에 사용된 데이터셋
- 40 종류의 알파벳 → background set (training set + validation set + test set)
- background set: (verfication을 위해) 모델을 학습하기 위해 사용된다. hyperparameter와 feature mapping을 학습함으로써 모델 성능을 향상시킨다.
- 10 종류의 알파벳 → evaluation set
- evaluation set: one-shot 분류 성능을 측정하기 위해 사용된다.
- 40 종류의 알파벳 → background set (training set + validation set + test set)
one-shot learning
- 과정: 20명 중에서 랜덤으로 2명을 뽑고
- 이 경우와 같이 10개의 새로운 클래스에 대해 one-shot learning을 한 경우 10-way one-shot learning이라고 한다.

Conclusion
- verification을 위해 CNN모델을 사용하여 one-shot 분류를 위한 모델을 제안
- Omniglot 데이터셋에 대해 SOTA 모델
- stroke에 local affine 변형을 사용하여 feature를 좀 더 잘 학습할 수 있도록 함
'인공지능 > 다양한 인공지능' 카테고리의 다른 글
| An Introduction to Machine Unlearning 논문 리뷰 (2) (0) | 2024.04.11 |
|---|---|
| An Introduction to Machine Unlearning 논문 리뷰 (1) (0) | 2024.04.11 |
| [강화학습] Markorv Decision Process (0) | 2024.01.21 |
| [Meta-Learning] Prototypical Networks for Few-shot Learning 논문 리뷰 (0) | 2023.08.24 |
| [Meta-Learning] Meta-Learning in Neural Networks: A Survey 논문 리뷰 (0) | 2023.08.10 |