이 논문은 Neural Architecture Search 분야의 기초가 되는 2017년 ICLR에 게재된 google brain의 Barret Zoph와 Quoc V. Le의 논문이다. CNN의 역사를 보면 VGGNet과 GoogleNet,... 으로 CNN의 구조(architecture)를 조금씩 바꾸어 좋은 성능을 내는 모델을 제안해왔다. 이와 같이 architecture에 따라 neural network의 성능이 달라질 수 있는데 이전에는 사람이 직접 좋은 architecture를 고안해왔다. feature 추출에서 SIFT, HOG처럼 feature design을 사람이 직접했었다가 feature design까지 기계가 찾아주는 딥러닝이 등장한 것 처럼 architecture를 찾아주는 것을 사람이 아닌 기계가 하도록 하자는것이 Neural Architecture Search의 아이디어이다.
Abstract
nueral network(인공 신경망)는 매우 유용하게 사용되고 있지만 설계하기 힘들다. 그래서 neural network를 RNN을 사용하여 설계하도록 나타내고, 이 RNN을 강화학습을 사용하여 예상되는 validation set에 대한 정확도가 최대가 되게끔 training한다. CIFAR-10 dataset을 사용하여 성능을 측정했을때 SOTA 모델보다 test error도 0.09퍼센트 낮고 testing 시간이 1.05배 빠르다. 또한 Penn Treebank dataset을 사용하여 성능측정했을때 SOTA 모델인 LSTM cell을 능가하는 성능의 recurrent cell을 만들수 있는데 이 data set에 대해 3.6 perplexity가 더 좋은 성능을 낸다.
Related Work
기계학습을 설계할 때 인간이 직접 해야하는 일을 줄여주는 AutoML 분야인 hyperparameter optimization은 기계학습에서 주요한 연구 주제이다. 그러나 이는 고정된 길이의 space에서 model을 찾을 수 있는, 즉 model의 구조와 network가 어떻게 연결되어 있는지는 다르게 특정짓지 못하기 때문에 한계가 있다. 비슷한 optimization 중 유명한 방법인 Bayesian optimization은 고정되어있지 않은 길이의 architecuture를 찾을 수 있게 해주지만 이 논문의 방법보다 덜 일반적이고 덜 유연하다.
NAS에서 사용되는 controller는 auto-regressive, 즉 이전의 예측값들을 조건으로 하여 hyperparameter를 한번에 예측해준다. 이 아이디어는 end-to-end seq2seq learning의 decoder에서 기인하였다. seq2seq과는 다르게 논문의 방법은 미분 불가능한 child network의 정확도를 최적화한다.
또한 해당 논문의 아이디어는 meta-learning을 참고하여 미래 task를 향상시키기 위해 한 task에서 학습된 정보를 사용하는 일반적인 framework가 되도록 하였다. 또다른 network를 update하기 위해 gradient descent를 사용하였고 또다른 network의 policy를 update하기 위해 강화학습을 사용하였다.
Method
먼저 convolutional architecture를 생성하기 위해 recurrent network의 간단한 사용방법을 설명하고 이 recurrent network가 뽑아낸 architecture의 예상되는 accuracy를 최대화하기 위해 policy를 어떻게 학습할 수 있는지 설명한다. 또한 model 복잡성을 높이기 위해 skip connection을 형성하는 방법과 training 속도를 높이기 위해 parameter server를 사용하는 방법을 보여줄 것이다. 그리고 마지막에는 또다른 key contribution인 recurrent architecture를 만들어낼 것이다.
RNN Controller로 Model description 나타내기
일단 NAS가 convolutional layer들로만 이루어진 feedforward neural network를 예측한다고 하면 다름 그림처럼 token들의 sequence로 hyperparameter들을 생성하도록 controller를 사용할 수 있다.

controller는 filter 크기, stride 크기, filter 개수와 같은 architecture의 hyperparameter의 값들을 RNN을 사용하여 예측한다. filter의 크기는 stride의 크기와 유의미한 관계를 가지고, 이전 layer의 hyperparameter들은 다음 layer의 hyperparameter와 유의미한 관계를 가지기 때문에 이 특성을 고려하여 RNN으로 controller를 구성하였다. 또한 controller를 RNN으로 구성하여 layer의 크기가 다양한 model을 만들 수 있다. 즉, 유연한 architecture를 만들 수 있다.
위의 네모들 중에서 한 열(column)의 세 개의 네모들을 하나의 cell이라고 할 때, 매 cell에서 input값과 hiddenstate값을 사용하여 계산하면 softmax classifier를 사용하여 output을 만들고 다음 cell의 input으로 들어간다(점선 화살표). 이를 반복하는데 layer의 개수가 어느정도 이상이 되면 멈춘다. 이때 여러개의 layer에 대한 filter 크기, stride 크기, filter 개수와 같은 hyperparameter값들이 샘플링되어 어떤 architecture가 만들어진다. 그러면 해당 architecture를 가지는 neural network를 만들어서ㅡ이렇게 만든 network를 child network라고 한다ㅡtraining시켜 어떤 accuracy를 얻어내면 이를 토대로 controller의 파라미터를 update한다. child network을 training시켜 accuracy를 얻어내는 것은 특정 CNN 모델을 forward-backward를 거쳐 weight값을 update한 후에 validation set에 대해 accuracy 값을 계산하는 것과 같은 과정이라 할 수 있다.
REINFORCEMENT로 training
controller가 만드는 output인 neural architecture는 어떤 architecture가 완벽하게 좋은 것인지의 정답 값을 알 수 없기 때문에 controller가 예측한 값과 비교할 정답 값이 없다. 이 때문에 controller의 파라미터를 update(최적화)하기 위해 강화학습을 사용한다.
여기서 action a는 (hyperparameter 값들을 뽑아서) architecture를 설계하는 것이 되고 이를 통해 만들어진 child network를 training하고 얻어낸 accuracy를 보상 값 R로 두어 보상 값이 최대가 되는 policy, 즉 architecture를 만들어도록 controller를 training한다.
이를 수학식으로 나타내면 다음과 같다.
controller의 parameter인 θ_c를 구하기 위해 policy-gradient method를 사용하였다. policy-based reinforcement learning은 최적의 policy를 찾아 이 policy의 action을 선택하는 것을 말하고 policy-gradient는 최적의 policy를 찾기 위해 policy값을 업데이트 시킴으로써 학습하는 것을 말한다. policy-gradient에서는 policy가 얼마나 정확한지를 나타내는 평가함수 J(θ_c)가 최대가 되도록 이 값의 gradient가 큰 방향으로 parameter를 업데이트(gradient ascent)하여 최적의 policy를 찾는다, 즉, 최적의 architecture를 만들어내는 controller의 parameter를 찾는다.
이 policy-gradient를 위해서 REINFORCEMENT라는 알고리즘을 사용하여 계산하였다.
REINFORCEMENT 알고리즘을 사용하면 위와 같은 식이 얻어지고 이를 계산하기 위해 근사를 시키고, 분산을 낮추기 위해 또 식을 변형하면 밑의 식이 얻어진다. 밑의 식의 b값은 이전 architecture의 정확도의 평균을 나타낸다고 한다. (강화학습에 대해 공부가 부족해서 수식에 대한 자세한 설명은 생략했다.)
최적의 architecture를 찾아낼 때 분산학습을 통해 더 적은 시간으로 계산해낼 수 있는데
위 그림처럼 parameter server에서 controller의 파라미터 θ_c를 나누어 가지고 있다가 이를 합쳐서 K개의 같은 controller replica(복제품)를 만들어내고 이들은 각각 동일한 m개의 child network replica를 만들어낸다. 이때 replica들은 parameter들을 서로 공유한다. 이렇게 해서 만들어진 m개의 child replica는 동시에 forward, backward를 반복하여 weight들을 update한다. 이는 m개의 mini batch로 child network를 나누어 training하는 것과 같다고 볼 수 있다. 이렇게 해서 각각의 controller의 parameter들은 update되고 K개의 controller로 인해 update된 parameter는 다시 S개의 parameter server에 나누어 저장된다.
복잡한 Architecture 생성
set-selection type attention을 사용하여 skip connections, branching layers 등을 만들어낸다.
: N개의 layer가 있을때 연결되는 이전 layer들을 나타내기 위해 N-1개의 (content-based sigmoid를 가지는) anchor point를 추가한다. 각 sigmoid는 controller의 현재 hiddenstate의 함수이고 이전 N-1 anchor points들의 이전 hiddenstate들이다.
h_j : j번째 layer에 대한 anchor point에서의 controller hiddenstate (j=0, 1, ..., N-1)
위의 식으로 멀리 떨어진 layer들이 연결되는 skip connection을 나타낸다(밑의 그림 참고). 그리고나서 이런 sigmoid로부터 어떤 previous layers가 현재 layer의 input으로 사용될지 결정하기 위해 sampling한다.
이렇게 되면 하나의 layer가 여러 input layer를 가지면 모든 input layer들은 높은 차원을 가지게 된다. 그래서 skip connection은 layer가 다른 layer와 호환되지 않거나, 어떤 layer가 input이나 output을 가지지 못하는 compilation failure가 발생할 수 있게 된다. 이를 해결하기 위해 세가지 방법을 고안해냈는데, 먼저 한 layer가 연결된 input layer가 없다면 (input) image를 input layer로 연결한다. 두번째로 연결된 output layer가 없는 layer들을, 마지막 hiddenstate를 classifier로 보내기 전에 마지막 layer를 output layer로 연결한다. 마지막으로, concatenate할 input layer의 size가 다를때, 작은 layer를 padding해서 큰 layer와 크기를 똑같이 맞춘다.
또한 learning rate, pooling, local contrast normalization, batchnorm과 같은 hyperparameter값들도 예측하게끔 할 수 있다. layer의 type을 추가하기 위해서는 RNN이 layer type을 예측할 추가적인 단계를 도입해야하고 그렇게 하면 다른 hyperparameter와 연관된다.
Recurrent Cell Architecture 생성
controller는 또한 RNN의 architecture를 구성하는 recurrent cell을 만들 수 있는데 특히 LSTM의 recurrent cell은 input인 x_t와 이전 cell의 output값인 h_{t-1}를 input으로 받아 h_t를 계산하여 다음 cell의 input으로 보내고 이전 cell값들을 포함하고 있는 c_{t-1}을 input값들과 어떤 연산을 하여 c_t를 다음 cell로 보낸다. 이런 cell을 찾는 controller 예시는 다음의 그림과 같다.
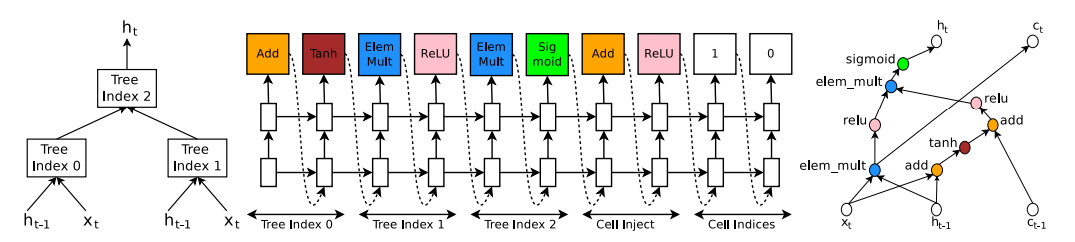
위의 그림을 보면서 controller가 어떻게 recurrent cell을 찾아내는지 보겠다.
가운데 그림에서 tree index 0, tree index 1 이렇게 되어있는 부분 각각을 하나의 block이라고 하면 가운데 그림은 controller의 5개 block부분을 보여주고 있다고 할 수 있다. 이는 controller가 recurrent cell에 필요한 hyperparameter값을 예측한 것인데,
먼저 tree index 0 부분을 보면 Add와 Tanh를 예측 한 것을 볼 수 있다. 이는 a_0 = tanh(W_1*x_t+ W_2*h_{t-1})의 계산이 필요하다는 것을 의미한다.
위와 비슷하게 tree index 1부분에서 Elem Mult와 ReLU를 예측했는데 이는 a_1=ReLU((W_3*x_t)⊙(W_4*h_{t-1}))의 계산이 필요하다는 것을 의미한다.
5번째 block인 Cell Index부분에서 두번째 예측값인 0은 a_0^{new}=ReLU(a_0+c_{t-1})의 계산을 만들게 하는데, 이전 cell에서 옮겨진 값인 c_{t-1} 값을 어느 값과 연산할 지에 대한 예측값이 그 예측된 “0”과 관련된 값이고 여기서는 tree index 0의 연산값인 a_0를 c_{t-1}와 연산하겠다는 것을 의미한다. 오른쪽 그림을 보면 c_{t-1}은 tree index 0의 예측된 연산인 add→tanh과 c_{t-1}가 연결되어있는 것을 볼 수 있다.
tree index 2에 대해 controller는 Elem Mult와 Sigmoid를 예측값으로 내놓았는데, 이는 a_2=sigmoid(a_0^{new}⊙a_1)를 의미 한다. 이때 tree의 가장 큰 index값이 2이기 때문에 h_t값은 a_2값이 된다.
마지막으로 Cell Index 부분에서 첫번째 예측값 1은 다음 cell로 넘겨줄 값인 c_t를 어떤 값을 사용해서 넘겨주느냐와 관련된 값인데 예측값이 1이므로 tree index 1의 output에서 activation을 거치기 전인 값을 c_t로 사용한다. 즉, c_t=(W_3*x_t)⊙(W_4*h_{t-1})을 계산한다. 오른쪽 그림을 보면 tree index 0의 activation function을 거치지 않은 계산 값인 elem_mult 노드가 c_t값이 되는 것을 볼 수 있다.
즉, Cell Inject는 이전 cell값인 c_{t-1}값과 계산하고 이 값을 사용할 값을 찾아낸 것이고 Cell Indices의 첫번째 예측값은 c_t를 사용할 값의 tree index를 나타내고 두번째 예측값은 c_{t-1}를 주입할 tree index를 나타낸다.
이 논문은 NAS 분야에서 거의 기초가 되는 논문이기 때문에 최근에 나온 NAS 논문들에 비해 매우 단순하고 비효율적인 아이디어라고 할 수 있다. 그렇기 때문에 experiments나 results에 대해서는 자세하게 언급하지 않을 것이다. 이 논문의 NAS는 child network를 만들 때마다 accuracy를 얻어내야 하므로 이를 training시켜야 한다. 만들어지는 child network가 매우 많은 데다가, 충분한 accuracy를 얻을때까지 network를 training하는데는 매우 많은 시간과 자원이 필요하다. 그렇기 때문에 여러 개의 비싼 GPU를 사용해도 NAS를 통해 좋은 성능의 network를 찾아내는데는 몇 달의 시간이 걸린다고 한다. 그래도 사람이 직접 고안해서 만들어낸 neural architecture와 견줄 정도의 성능을 가진 neural architecture를 기계가 찾아내었다는 점에서 매우 중요한 논문이 된다. 또한 이 논문 이후로 NAS 관련한 연구들이 활발하게 진행되었다. 앞으로도 계속 포스팅할 ENAS, DARTS 논문들이 그 예가 된다.
'NAS' 카테고리의 다른 글
| DARTS: Differentiable Architecture Search 논문 리뷰 (0) | 2022.01.18 |
|---|