해당 논문은 미분법을 사용하여 architecture search의 확장성 문제를 다룬다. discrete하고 미분불가능한 search space를 다루는 진화 혹은 강화학습을 적용한 기존 접근법과 다르게, 논문의 방식은 architecture 표현의 연속적인 relaxation에 기초하여 gradient descent를 사용하여 architecture 탐색을 효율적으로 만든다. CIFAR-10, ImageNet, Penn Treebank, WikiText-2에 적용한 광범위한 실험은 이 알고리즘이 image classification에 대해 높은 성능의 convolutional architecture와 language modeling에 대해 recurrent architecture를 발견하는 속도를 빠르게 한다는 것을 보여준다, 미분 불가능한 SOTA 기술보다 수십배 빠른 반면에. 우리의 구현은 효율적인 architecture search 알고리즘에서의 더 깊은 연구를 public하게 가능하게 하도록 한다.
밑의 내용은 DARTS 논문의 method 부분에 해당 되는 내용이다.
Search Space
- NASNet의 cell-based search space를 따라 학습한 cell을 쌓아 architecture를 형성
- 하나의 cell은 N개의 node들이 정렬된 순서로 구성되어있는 DAG이다. 각 노드 x^(i)는 latent representation이고 각 edge (i, j)는 x^(i)를 변형하는 operation o^(i,j)를 나타낸다.
- 각 cell은 모두 두 개의 input node와 한 개의 output node를 가지는데
- convolution cell의 경우, 이전 두 layer의 output이 cell의 두 개의 input node가 되고
- recurrent cell의 경우, 현재 step의 input과 이전 step에서 carried된 state값이 cell의 두 개의 input node가 된다
- cell의 output node는 cell의 중간 노드(input노드와 output 노드 사이에 있는 노드)들 값들이 reduction operation(concatenation과 같은)이 적용된 값이 된다.

- 각 중간 노드는

위의 연산을 통해 계산된다. operation 중에 zero operation은 두 노드가 연결되어 있지 않음을 나타내고 이 연산으로 operation의 학습량을 줄여줄 수 있다. (zero operation은 해당 edge를 학습할 필요가 없게 하니까 operation 학습량을 줄여줄 수 있다.)

Continuous relaxation and optimization
cell의 각 edge가 convolution, max pooling, zero과 같이 가능한 operation들 중 어떤 operation을 선택해야 좋은 성능의 architecture가 될지 알기 위해 이전의 NAS 알고리즘에서는 가능한 모든 operation들의 조합을 만들어 놓고 그 중에서 성능이 좋은 것을 선택하는 방법으로 architecture를 찾았다. 그러나 생각해보면 이는 비효율적인 방법이다. optimization 하면 gradient descent방법이 유명한데, 왜 여태까지는 미분을 사용하여 architecture를 찾지 못했을까? 이는 search space가 discrete domain이어서 미분이 불가능했기 때문이다. O={convolution, max pooling, ..}와 같은 operation 집합이 search space가 되었기 때문이다. 그래서 이 논문에서는 미분을 사용하여 optimization을 하기 위해서 domain을 미분가능한 continuous domain으로 만들어주는(relaxation) 방법을 소개한다.
O는 가능한 연산들의 집합을 말하고 o(x)에서 o( )는 해당 x에 적용되는 operation의 함수를 말한다. search space를 연속적으로 만들려면, 여러 operation 중에 하나, 이렇게 단정적으로 operation을 선택해야 하는 것을 모든 가능한 operation에 대해 softmax를 사용하여 relax시킨다.

위 식을 살펴보면 mixed operation인 ㆆ(x)값은 가중치인 α값과 x에 특정 operation을 적용한 o(x)값을 곱한 값들의 합인 것을 볼 수 있다. 즉, 각 operation들의 계산 결과 값을 가중치를 통해 조절하여 하나의 값으로 만들었다. 이 가중치 α(i,j)값을 조절하여 (i,j) edge에서 어떤 operation을 사용해야 좋은 성능이 architecture를 선택할 수 있는 지를 알 수 있게 된다. α값은 각각의 operation들에 대한 가중치 값을 가지고 있어야 하므로 가능한 operation 개수를 dimension으로 가지는 vector로 표현된다.
search의 마지막 단계에서 mixed operation중 가중치(α) 값이 가장 큰 값으로 operation을 선택해서 mixed operation 대신 discrete architecture가 얻어진다. 각 edge의 α 값들의 집합은 가능한 operation들의 가중치 값들을 모든 edge에 대해 가지고 있으므로 architecture를 나타내는 값이라고 할 수 있다.
어떤 architecture를 찾고 나면 training을 해서 weight값들을 update해야 한다. 따라서 우리가 optimization해야 하는 것은 α값과 찾은 architecture의 weights값이다. 논문에서는 training loss가 최소가 되는 weights값을 찾고 이 weights값을 가지면서 validation loss값이 최소가 되는 α값을 찾도록 한다. 이는 bilevel optimization problem을 가지게 되고 training loss값이 최소가 되는 weight값을 찾고 해당 weight값을 가지는 alpha가 validation loss가 최소가 되는 방향으로 gradient descent를 적용하여 α값을 찾는 것을 계속 반복하여 최적의 α값과 weight값을 찾는다.

Approximate architecture gradient
그런데 inner optimization인 w*를 찾는 과정이 연산이 복잡하므로 해당 식을 다음과 같이 근사시켜 최적의 w값을 찾도록 한다.

w*를 구하기 위해 수렴할때까지 training하도록 연산하지 않고 하나의 training step으로도 최적의 w값과 유사한 값을 얻을 수 있다는 아이디어를 참고하여 근사시켰다고 한다. 이 때 참고한 논문은 (1), (2), (3)이라고 한다.
이렇게 해서 DARTS 논문의 알고리즘을 정리해보면 다음과 같다.

위 그림에서 (6)식을 (7)로 풀어 쓸 수 있는데

(7)의 식에서 두 번째 항이 계산 복잡한 metrix-vector연산을 해야하므로 여전히 계산하기 힘들다. 그러므로 이를 유한 미분 근사를 사용하여 (8) 식으로 나타낼 수 있다.

근사시킨 위의 식으로 계산을 하게 되면 계산 복잡도가 O(|α||w|)에서 O(|α|+|w|)로 줄어들게 된다.
Deriving discrete architecture
최적의 mixed operation 값을 찾았다면 섞여있는 것들 중 operation을 선택하여 architecture를 생성해야 한다. 즉, 실제 architecture는 discrete하므로 continuous한 search space를 다시 discrete하게 만들어줘야 한다. 방법은 α값이 가장 큰 k개의 operation을 선택하여 architecture를 구성하면 된다. convolution cell은 k=2, recurrent cell의 경우 k=1로 값을 설정한다고 한다.

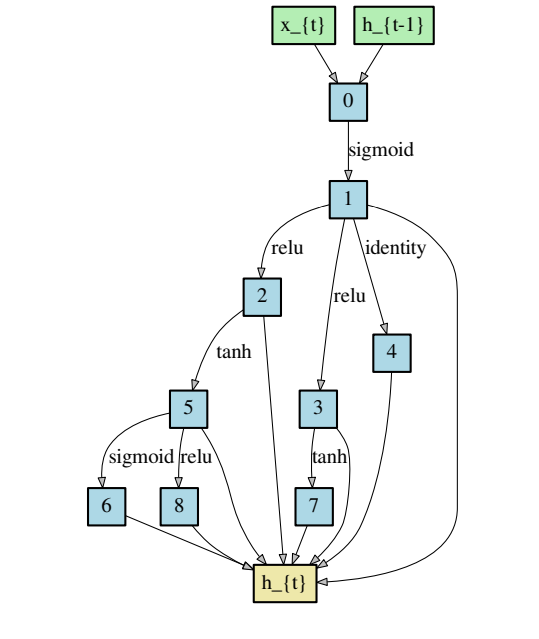
위의 그림처럼 convolutional cell의 경우 중간 노드가 두 개의 operation의 결과 값을 받고, recurrent cell의 경우 중간 노드가 한 개의 operation의 결과 값을 받는 것을 볼 수 있다.
DARTS 논문은 gradient-based로 neural architecture를 성공적으로 search하는 거의 첫 모델이라고 할 수 있고 이 이후로 많은 gradient-based의 NAS가 연구되었다. 새로운 방법으로 architecture를 search 했음에도 불구하고 이전의 NAS모델 중 성능이 가장 좋은 모델과 견줄 정도의 성능을 가지고 architecture를 찾는데 1GPU days만큼의 시간이 걸릴 정도로 효율적으로 architecture를 찾을 수 있다.
(1) Model-agnostic meta-learning for fast adaptation of deep networks(2017)
(2) Scalable gradient-based tuning of continuous regularization hyperparameters(2016)
(3) Unrolled generative adversarial networks(2017)
'NAS' 카테고리의 다른 글
| Neural Architecture Search with reinforcement learning 논문 리뷰 (0) | 2022.01.05 |
|---|