'Efficient Processing of Deep Neural Networks' 글들은 Efficient Processing of Deep Neural Networks: A Tutorial and Survey 논문을 정리한 글들이다.
이 논문은 흔히 NPU, TPU로 알고 있는 DNN 가속기와 관련된 논문들을 모아 정리해놓은 survey 논문이며
효율적인 DNN을 위한 소프트웨어적인 노력과 하드웨어적인 노력을 다룬다.
전자 부분을 'DNN' 게시글에, 후자 부분을 'HW for DNN Processing' 게시글에 포함시킬 예정이다.
이번글 'Efficient Processing of Deep Neural Networks - DNN(1)'에서 다룰 내용은 다음과 같다.
- AI 종류
- 추론, 학습
- 적용
AI 종류

매우 폭넓은 분야를 가리키는 AI에 속하는 여러 인공지능 모델들의 관계를 그림으로 나타내면 위와 같다.
흔히 사용하는 단어인 AI, 머신러닝, 딥러닝의 차이를 헷갈려 하는 경우가 많은데, 셋은 위 그림을 보면 알 수 있듯이 머신러닝은 AI에 포함되고, 딥러닝은 머신러닝에 포함되는 관계를 가진다. 셋의 차이를 비교하면서 개념을 살펴보겠다.
AI(Artificial Intelligence, 인공지능)는 인간처럼 목표를 이룰 수 있는 능력을 가진 기계를 말한다.(John McCarty, 1950s) AI는 이런 능력을 가진 프로그램을 사람이 직접 구현하는 경우를 말하는 반면, 머신러닝(ML)은 명시적으로 프로그래밍되지 않고 학습하는 능력을 가진 기계를 말한다. 이렇게 말하면 조금 이해하기 어려울 것 같아, 더 쉬운 설명을 위해 '핸즈 온 머신러닝'에서 든 예시를 가져와보겠다.
스팸을 걸러내는 프로그램인 스팸 필터를 만들때 머신러닝이 아닌 AI로 구현을 한다고 하면
스팸 필터 프로그램은
1. 스팸에 주로 나타나는 단어나 구절이 무엇인지를 직접 찾고
2. 해당 단어나 구절이 들어가는 메일을 찾아서 스팸을 감지하도록
짜게 될 것이다.
=> 이 경우 해당 단어나 구절을 찾는게 어렵고, 스팸에 자주 나타나는 단어로 예를 들어 '저렴한'을 찾게 되어서 이 단어를 포함한 메일을 스팸으로 걸러냈는데, 스팸 메일 발송자가 '저렴한'을 '싼'으로 변경하여 스팸을 보내기 시작하면 이 스팸은 '저렴한'을 포함하고 있지 않으므로 스팸으로 걸러지지 않게 된다. 이를 수정하기 위해서는 '싼'이라는 단어를 추가로 걸러내도록 프로그램을 직접 수정해야 한다.
이제는 스팸 필터를 머신러닝으로 구현하는 경우를 생각해보자.
머신러닝으로 구현할 경우 스팸에 주로 나타나는 단어나 구절을 기계가 학습을 통해 자동으로 찾아서 스팸을 걸러준다.
=> 이 경우 스팸의 단어를 쉽게 찾을 수 있고, 스팸 메일 발송자가 단어를 바꿔서 스팸을 발송한다 하더라도, 기계는 학습을 통해 스팸에 자주 나타나는 단어를 찾아낼 수 있다.
이번엔 머신러닝과 딥러닝을 비교해보겠다.
학습을 통해 만든 모델이 좋지 않은 모델일때 설정된 파라미터(매개변수) 값을 변경하여 더 좋은 모델로 업데이트를 시켜야 하는데, 머신러닝은 파라미터 변경을 사람이 직접하는 반면, 딥러닝은 파라미터 변경까지 기계가 직접하는 경우를 말한다. 그 업데이트는 딥러닝의 경우 backpropagation(역전파)을 통해 이루어진다. 딥러닝과 DNN(Deep Neural Network)는 같은 말이라고 볼 수 있는데, DNN은 layer(계층)가 3개 이상인, hidden layer가 1개 이상인 neural network를 말한다. layer와 hidden layer를 이해하려면 neural network(인공 신경망)에 대해 더 공부해보면 알 수 있다. 인공신경망에 대해 친절하고 쉽게 설명해주는 블로그들이 많으므로 검색해서 읽어보면 도움이 될 것 같다.
이 외에도 다른 AI 모델을 살펴보자면
Brain-inspired는 ML중에서 인간의 뇌 동작 방식을 토대로 학습 부분을 구현한 것을 말한다.


뇌에서 신호는 이전 뉴런의 축삭돌기(axon) -> 이번 뉴런의 수상돌기(dendrite) -> 뉴런(neuron)에서 그 신호로 어떤 연산이 이루어진 후에 그 신호를 axon을 통해 다음 뉴런으로 전달된다. 뉴런과 뉴런사이의 연결을 시냅스(synapse)라고 하는데, 이 시냅스가 신호의 크기를 조절하면서 다음 뉴런으로 넘기는 과정에서 학습이 일어난다는 성질을 이용하여, 인공 신경망에서 기기를 학습하기 위해 axon으로 들어온 (입력)값에 가중치(weight)를 곱해서 입력값을 조절하여 다음 뉴런으로 전달하여 입력값을 사용하도록 구현하였다.
이와 같이 뇌의 뉴런의 활동 방식을 활용하여 구현한 인공지능을 Brain-inspired라고 한다.
또한 spiking은 brain-inspired 중에서 더 뇌의 특성을 살려 만든 모델을 말한다.
추론, 학습
머신러닝(machine learning) 모델은 이름 그대로 많은 데이터를 이용해서 학습을 한 후에 새로운 데이터로 어떤 예측을 하거나 분류를 하는 등의 일을 수행한다. 여기서 전자 과정(어떤 데이터들을 학습하는 것)을 학습(Training)이라고하고, 후자 과정(어떤 예측을 하거나 등)을 추론(Inference)라고 한다.
조금 더 정확한 정의를 말하자면 학습은 모델의 가중치 값을 원하는 방향대로 결정하는 것을 말하고, 추론은 해당 모델에서 어떤 output을 계산해 내는 것을 말한다.
예를 들면 모델이 많은 다른 고양이 사진들을 학습하게 한 후(A), 학습했을 때 사용하지 않은 다른 고양이 사진을 주고 그게 고양이 사진인지 판별하게 하는 경우(B), A과정이 학습이고, B과정이 추론이다.(밑그림 참고)

앞에서 딥러닝은 기계가 스스로 정확도를 높이기 위해 업그레이드를 한다고 하였다.
어디가 얼마나 잘못되었는지를 알아야 모델을 더 정확한 것으로 만들 수 있을 것이다. 추론을 통해 얻어낸 output값과 이상적인 output값의 차이를 loss값이라고 한다. weight값에 따른 loss값을 나타낸 함수를 loss function이라고 하는데, loss값이 작을수록 정확도가 높은 모델이라고 할 수 있으므로 loss값이 최소가 되는 weight를 찾는 것이 목표가 된다.

고등학교 수학시간 때 배웠던 미분값이 0이 되는 지점을 찾으면 함수의 최솟값을 구할 수 있는다는 원리를 이용하여 loss function의 최솟값을 구할 수 있다. 이때 사용하는 방법은 gradient descent 방법인데 gradient값(미분값과 비슷한 것이라고 이해하면 된다)이 0이 되는 방향으로 weight값을 조금씩 변경하여 loss값이 최소가 되도록 weight값을 수정한다.

왼쪽 식처럼 weight값을 업데이트하게 된다.
여기서 7처럼 생긴 문자의 변수는 학습률(learning rate)이라고 하는 weight가 한번 업데이트되는 정도를 조절하는 값이다. 학습률이 클수록 빨리 최솟값에 접근할 수 있다.
하지만 loss값이 최소가 되는 weight를 찾는데 위의 식으로는 충분하지 않다. 왜냐하면 DNN 같은 경우 여러 개의 layer를 가지고 있고, 따라서 weight도 여러 개이다.
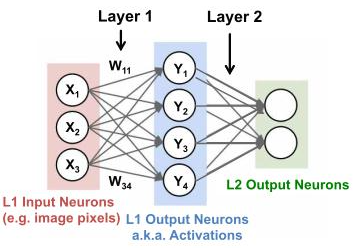
왼쪽 사진처럼 각 layer에서 다른 weight를 가지고 있기 때문에 각각의 weight를 어떻게 바꿔야 할지를 계산하는데 위 식으로는 충분하지 않다.
그래서 사용하는 것이 backpropagation(역전파) 알고리즘인데 이는 각 layer의 weight값들이 loss값에 얼마나 영향을 미치는지 구하는 방법이다. output layer(맨 오른쪽 layer)에서 input layer(맨 왼쪽 layer)로 loss값과 각 loss에 대한 weight의 편미분값을 넘겨주기 때문에 거꾸로 값을 보낸다해서 역전파 알고리즘이라고 한다. 연쇄 법칙을 이용하여 각 layer의 weight에 대한 loss의 편미분값을 구한다.
적용
- 이미지와 영상(video):
computer vision은 영상으로부터 의미있는 정보를 뽑아내야 하는데 이 일에 DNN을 사용한다. 대표적으로는 image classification, object localization and detection, image segmentation, action recognition이 있다.(영상과 이미지의 관계-많은 이미지가 연속되면 영상이 된다)

- speech와 언어:
대표적으로는 speech recognition, 자연어 처리(natural language processing, NLP), audio generation이 있다. 자연어처리는 번역기 등에 사용되며 CNN과 같이 현재 많이 사용되는 DNN 모델이다.
- 의학분야:
피부암, 뇌종양, 유방암 탐지 등에 사용되고 있다.
- 게임 play:
주로 강화학습을 사용하여 게임을 하는 DNN을 만든다. 구글 딥마인드 회사가 개발한 알파고와 Atari 게임을 play한 모델이 잘 알려져 있으며, 대부분 사람을 능가하는 게임 수행 능력을 보여주고 있다.
https://www.youtube.com/watch?v=V1eYniJ0Rnk&ab_channel=TwoMinutePapers
- 로봇분야:
대표적으로는 어떤 물건을 쥐거나 집을 수 있는 로봇 팔, 자율주행 자동차가 있다.
※ 공부하고 있는 단계라 내용에 부족한 부분이 많습니다. 조언이나 지적은 감사히 받아들이고 수정하겠습니다.