이번글 'Efficient Processing of Deep Neural Networks - DNN(2)'에서 다룰 내용은 다음과 같다.
- DNN의 종류
- 유명한 CNN 모델
DNN의 종류
DNN을 크게 두 종류로 나눌 수 있다.
feedforward neural network:

input 부분에서 output 부분까지 연속적으로 이전레이어의 output 값을 받아서 계산하고.. 이를 한 방향으로 연산을 진행한다. recurrent network와 달리 순서가 있는 입력에 대해서 순서를 고려하지 않고 출력해준다. 예를 들어 input1, 2, 3순서대로 입력이 들어왔다면 출력은 output1,3,2와 같이 순서와 관련 없이 출력될 수 있다. 이미지가 어떤 물체를 포함하고 있을 확률과 같은 일을 할 수 있다.
recurrent neural network(RNN):
network의 중간 연산값이 내부에 저장되고 이후 layer의 input으로 사용된다. 이를 위해 내부에 저장공간을 필요로 하고 순서가 있는 입력에 대해서 처리가 가능하다. input1, 2, 3 순서대로 입력이 들어왔다면 해당 순서대로 출력이 된다(output1, 2, 3). 자연어 처리, 영상 처리와 같은 일을 할 수 있다.
DNN은 FC(fully connected) layer으로만 구성될 수 있는데, FC layer에서는 모든 input activation이 모든 output activation에 대해서 가중합으로 구성한다. node를 activation이라고도 한다. 밑의 그림을 보면 하나의 input node와 그 다음 layer의 모든 node들이 연결되어있는 것을 볼 수 있다.

이 경우 상당히 많은 양의 저장공간과 연산량을 요구하게 된다.
그러나 다행히, 몇몇의 연결을 weight값을 0으로 만듦으로써 제거해도 정확성에 영향을 안주게 될 수 있는데, 이를 sparsely connected layer라고 한다.
더 효율적인 방법으로 output에 영향을 주는 weight의 개수를 제한할 수가 있는데, 고정된 적은 개수의 weight만으로 각 output을 계산해낼 수 있다. 심지어는 모든 activation에 대해 같은 weight을 사용하여 연산을 할 수있다. 이를 weight shared라고 부르며 weight의 저장공간을 대폭 줄일 수 있다. convolution이라는 연산을 통해 이 연산을 해낼 수 있는데,
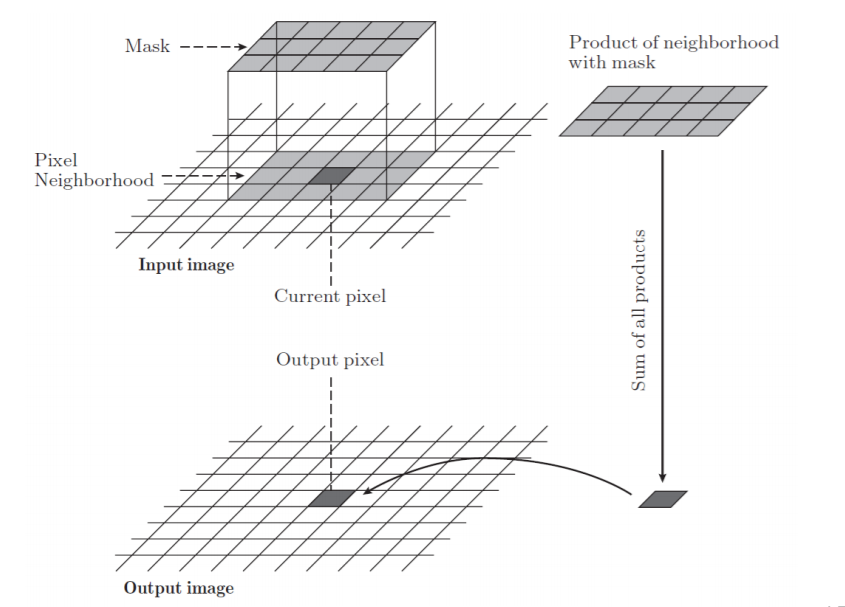
어떤 하나의 output을 계산하기 위해 input activation의 해당 위치의 주변 값들(pixel neighborhood)을 사용한다. 이렇게 어떤 값을 계산하는데 영향을 준 주변 픽섹들의 영역을 receptive field라고 한다. 모든 activation에서 같은 weight를 사용하므로 weight는 모든 output에 영향을 준다고 할 수 있다. 이와 같은 convolution연산을 기본으로 하는 layer를 convolution(CONV) layer라고 한다.
CNN은 Convolution Neural Network의 약어로, 여러 CONV layer로 구성되어있다. 각 layer는 input data의 연속적으로 높은 수준의 추상화한 값을 만들어서, 필수적이고 고유한 정보를 담는 정보가 되는데 이를 feature map(fmap)이라고 한다. input fmaps이 여러 장이 모여있는 데, 그 개수가 C라는 변수로 표현되었다. input fmaps나 filter가 여러장 있는 경우 각각을 channel이라고 하고, 현재 filter의 channel은 C개, ifmaps(input fmaps)도 C개, ofmaps(output fmaps)는 M개 있다고 할 수 있다. 밑의 그림에서 M개의 filter와 N개의 ifmaps를 convolution연산하여 N개의 ofmaps을 생성하였다. 몇몇 변수의 값이 겹치는 것을 볼 수 있다.

먼저 filters와 ifmaps는 convolution의 정의에 의해 같은 채널 값을 가져야 한다.(1대1 대응되어야 함) 또 filters의 개수와 ofmaps의 채널 개수가 M으로 같은 것을 볼 수 있다. 이는 여러 개의 ifmaps와 하나의 filters가 convolution연산하면 채널 한 개의 ofmaps들이 ifmaps개수만큼 생성된다. 그래서 filter의 개수와 ofmaps의 채널 개수가 같은 것이다.
;
유명한 CNN 모델
CNN의 정확성을 높이기 위해 다양한 모델이 고안 되어왔는데, layer의 개수, layer type, layer shape, layer간의 연결 등을 변화시켜 새로운 모델을 만들어 내었다.

각 모델의 구조를 보기 전에 CNN의 기본 구조를 보겠다.

뭉크의 절규 그림은 input을 말하고, input이 모델로 들어오면 CONV layer를 여러개 거쳐 feature가 추출되고나서 FC layer를 통해 class score값이 계산되어 분류된다. 즉 여러 개의 CONV layer + 1~3개의 FC layer로 구성되어 있다. 각 CONV layer는 convolution 연산을 하고, activation function을 통해 non-linearity를 얻고, 경우에 따라서 normalization과 pooling을 적용하기도 한다. normalization은 연산결과 계산된 값이 이전 layer의 값들과 많이 달라지지 않도록 조정하는 것을 말하고, pooling은 계산된 값의 필요없는 일부분을 버려 가지고 있는 feature을 더 강조하고, 연산량을 줄이는 역할을 한다. 그리고 각 FC layer는 앞에서 봤던 fully connected의 연산과 activation function을 적용하여 class score값을 계산한다. class score은 각 class에 대한 score값을 의미하고 보통 높은 score의 class로 분류가 된다.
CNN의 기본 구조를 봤으니 각각의 유명한 CNN모델을 살펴보겠다.
LeNet

LeNet은 1989년에 처음 소개된 CNN 모델이다. 6만개의 weight를 사용하였고,한 개의 이미지당 34만개의 MAC(곱셈과 덧셈) 연산을 하였다. 상업적으로 성공을 거둔 첫 CNN 모델이고, ATM에서 수표 예금의 숫자를 인식하는데 사용되었다.
AlexNet

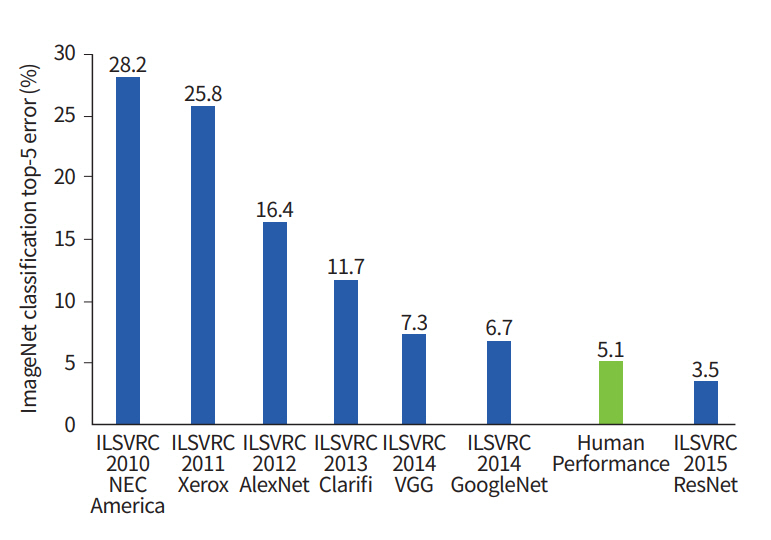
AlexNet은 2012년에 ImageNet에서 1등을 한 모델이다. ImageNet은 256x256 pixels짜리의 수많은 color image를 대상으로 1000개의 class로 분류하여 가장 낮은 error를 내는 순으로 수상을 하게되는 대회이다. LeNet과 다른점은 AlexNet에서 더 높은 정확도를 주는 ReLU를 activation function로 사용하였고, filter의 채널 개수를 줄이기 위해 CONV layer를 두 개의 group으로 나누어 각각 절반의 채널을 가지도록 구성하였다. 이렇게 CONV layer의 채널을 절반으로 줄이면 원래보다 절반의 채널의 filter를 사용할 수 있기 때문에 적은 weight를 사용할 수 있다. AlexNet은 6100만 weight와 7억개의 MAC 연산을 포함하였고 16.4%의 정확도(Top-5 error)를 가진다.
ImageNet challenge에서 정확도를 판단할때 Top-5 rate/error와 Top-1 error 두 종류로 정확도를 판단한다. Top-5 error는 error가 가장 적게 나온 상위 class 5개에 정답이 포함이 되는 경우가 어느정도 되는지에대한 error이고, Top-1 error는 error가 가장 적게 나온 class가 정답 class일 경우가 어느정도 되는지에대한 error이다. 때문에 Top-1 error가 더 까다로운 조건에서 측정된 정확도라 볼 수 있다.
Overfeat
Overfeat은 AlexNet과 비슷하게 5개의 FC layer와 3개의 CONV layer로 구성 되어있지만, AlexNet보다 많은 수의 weight을 사용하였고 layer2를 두 그룹으로 나누지 않았다. 그 결과 약 1.46억개의 weight와 이미지 하나 당 2.8G개(1G = 1x10^9)의 MAC연산을 포함하였다. Overfeat은 fast와 current, 두 개의 모델을 가지고 있는데 current 모델의 경우 fast 모델보다 1.9배 많은 MAC 연산을 포함하고 0.65% 더 낮은 top-5 error를 가진다.
VGG-16

이름에서 짐작할 수 있다시피 VGG-16은 앞의 모델보다 더 깊은, 16개의 layer로 구성되어있다. 더 layer를 깊게 쌓는 대신에, 연산과 weight를 줄이기 위한 방법을 모색했는데, filter의 크기를 줄이고 더 깊게 layer를 구성하면, 사용되는 weight 개수가 줄어든다는 것을 이용하였다.
5x5 input의 하나의 픽셀의 output을 내기위해 5x5 filter를 사용하면 layer한번 만에 만들어 낼 수 있는데, 3x3 filter를 사용하면 두 번의 layer를 거쳐서 같은 결과의 하나의 output을 낼 수 있게 된다.
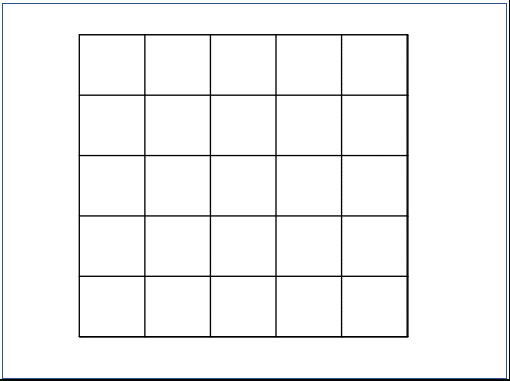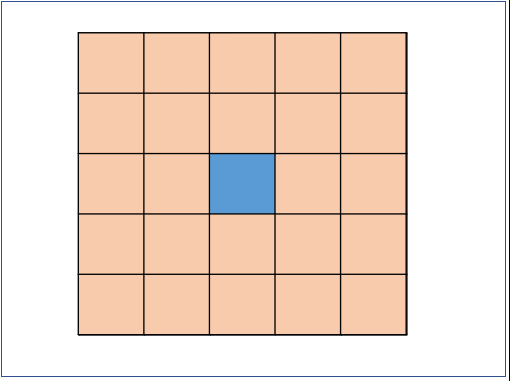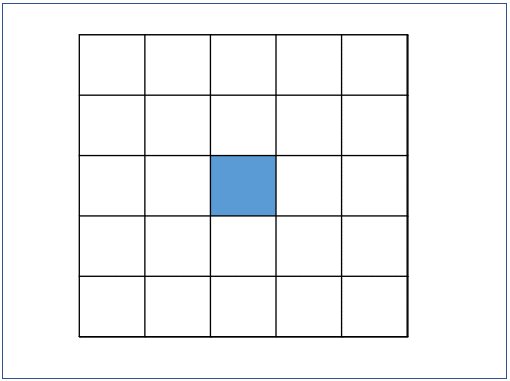
위의 그림은 5x5 크기의 input fmap에 5x5 크기의 filter로 convolution 연산을 하면 한번에 한 pixel의 output을 생성할 수 있다. 반면에 같은 크기의 input fmap에 3x3 크기의 filter로 convolution 연산을 하면 9개의 pixel의 output을 생성하게 된다. 이 9개의 output pixel에 다시한번 3x3 filter로 convolution을 해줘야 하나의 output pixel이 생성된다. 따라서 3x3 filter로 5x5 filter와 같은 결과의 convolution을 하기 위해서는 두 개의 3x3 filter를 사용해야 한다.


5x5 filter 한 개와 3x3 filter 두 개의 weight을 비교해보면 25>9로 더 작은 filter를 여러번 사용한 것이 더 적은 weight가 들고 convolution연산도 따라서 적게 든다. VGG-16은 약 1.38억 개의 weight을 사용하고 15.5G의 MAC이 일어난다.
GoogLeNet

GoogLeNet은 VGG-16, VGG-19보다 더 깊은 22개의 layer로 구성되어있다. GoogLeNet에서 중요하게 봐야하는 것은 inception module을 사용하였다는 것이다. inception module은 CONV layer를 병렬로 구성하여 input fmap의 채널들을 여러 부분으로 나누어서 동시에 convolution 연산을 하고 다시 하나의 output fmap으로 합쳐서 다음 layer로 넘겨주는 방법이고, training의 속도를 높이기 위해서 사용되었다. 또한 병렬적으로 CONV layer를 배치함으로써 model의 input부터 output까지의 거리를 좁혀, vanishing gradient problem 문제를 줄인다.(vanishing gradient problem은 ResNet 설명 참고) 밑의 그림에서 보면 inception model에서 1x1 filter의 CONV layer가 포함되어있는 것을 볼 수 있는데 이는 input fmap의 channel의 수를 작은 값으로 조절하여 연산량을 줄이는 효과가 있다. 이런 목적으로 1x1 filter를 적용하는 것을 bottleneck이라고 한다. 여담으로 googLeNet에서 대문자 철자가 이상해보이는데, 이는 가장 처음으로 상용화되었던 CNN의 LeNet을 기리기 위해 googleNet이아니라 googLeNet으로 이름을 지었다고 한다.

ResNet

ResNet은 Residual Net으로 알려져 있는데, 이전 모델보다 더 깊은 34개 이상의 layer를 사용한다. 모델이 깊어질수록 더 복잡한 feature을 추출할 수 있어서 더 높은 정확성을 낼 수 있다. 그런데 왜 이전에는 이렇게 깊게 layer를 구성하지 않았을까? layer를 어느정도 이상 많이 쌓으면 생기는 치명적인 문제인 vanishing gradient problem 때문이다. backpropagation과정에서 loss값에 대한 각 layer에서의 미분값을 모델의 output에서 input쪽으로 전달하는데, 미분의 특성상 작은값을 계속 미분하면 매우 작은 값이 되어버리기 때문에 input에 전달되는 미분값은 0에 가까운 값이 되어서 backpropagation이 제대로 되지 못하는 현상이 발생한다. 이를 vanishing gradient problem이라고 한다. 이런 문제를 해결하기 위해 shortcut module이라고 불리는 residual connection을 사용하여 모델을 구성하였다. 이전 layer의 값을 다음 layer에 최대한 유지하기 위해 이전 layer의 값을 아예 가져와서 convolution값과 합치는 것이다. 여기에도 1x1 CONV layer를 사용하여 연산량을 줄였다. 이런 방법을 통해 ResNet은 최대 152개까지 layer를 쌓아도 높은 정확도를 얻을 수 있었다.

layer의 수가 많을수록 정확한 모델을 얻을 수 있지만, layer의 수가 많을수록 수반되는 문제점ㅡ많은 연산량, vanishing gradient 등ㅡ떄문에 처음부터 많은 layer를 사용하지 못했다. 이러한 문제점을 보완하기 위해 다양한 방법을 생각해냈고, 결국 34개 이상의 layer를 사용한 ResNet을 만들어냈으며, 이 친구는 사람보다도 높은 분류 정확도를 가진다고 한다.
※ 공부하고 있는 단계라 내용에 부족한 부분이 많습니다. 조언이나 지적은 감사히 받아들이고 수정하겠습니다.
[그림 출처]